What ‘Good’ AI Governance Looks Like in the First 90 Days
AI moved from experiments to everyday tools almost overnight. Your sales team has AI notes in their meeting app. Contact center leaders are piloting AI agents. Operations is testing copilots against internal documents.
The risk is that governance shows up late. When that happens, costs spiral, shadow AI grows, and security teams are left cleaning up behind tools they never approved.
The good news is that “good enough” AI governance doesn’t require a 200-page policy or a new committee for every decision. In the first 90 days, you can put lightweight policies, approval tollgates, AI guardrails, observability, ownership, and AI literacy in place that guide usage without killing momentum.
Here we outline what good early-stage AI governance looks like, taking advice discussed in our recent webinar and turning it into a 90-day framework you can use right away.
Good AI Governance TL;DR
- Good AI governance does not require a heavy program on day one. In the first 90 days, organizations can put practical policies, approval checkpoints, AI guardrails, and ownership in place without slowing useful experimentation.
- The first phase should focus on defining scope, standing up a lightweight working group, drafting a simple AI use policy, and creating a basic inventory of AI already in use.
- The next phase should introduce clearer ownership, lightweight approval tollgates, better observability, and stronger alignment with existing security practices.
- By days 61 to 90, the focus should shift to AI literacy, success metrics, and a first-pass governance playbook that can evolve over time.

Why AI Governance Can’t Wait for a Formal Program
In the cloud, relatively few people could provision infrastructure on their own. However, in AI, almost anyone can activate a new feature, buy a per-seat assistant, or launch a small application on a low-friction platform.
That creates three immediate problems:
- Unowned spend, where finance and IT can see costs rising but can’t clearly tie them back to specific AI initiatives
- Unclear risk, where data may be flowing into external tools without proper review
- Unmanaged expectations, where business teams assume AI will work around weak processes or poor data
Waiting for a formal program only makes these issues harder to untangle. Good AI governance starts when experimentation starts. The goal in the first 90 days is to create enough structure, visibility, and AI guardrails for teams to move forward safely and intentionally, without hindering innovation. Check out this short clip from our webinar where we discussed AI governance.
What Is AI Governance?
AI governance is the operating model an organization uses to guide how AI is selected, approved, monitored, and improved over time. It defines who owns decisions, what rules apply to data and tools, how risk is reviewed, how success is measured, and how leadership maintains visibility as AI usage expands.
In practice, strong AI governance should answer questions like:
Which AI tools and features are approved today?
What data can and can’t be used with those tools?
Who reviews new AI use cases?
How are costs, outcomes, and risks tracked?
Which teams are accountable for policy, architecture, security, and business results?
AI governance is broader than a single policy document. It is the framework that helps organizations move from ad hoc AI usage to accountable, repeatable decision-making.
Principles of “Good” Early-Stage AI Governance and AI Guardrails
Before you design anything, align on a few principles.
- Start lightweight and evolve over time: You don’t need a mature governance structure on day one. A small working group, a short internal policy, and a basic approval checkpoint can reduce risk quickly while giving the organization room to learn.
- Make governance shared across the business: AI governance shouldn’t sit entirely with IT. Security, data, finance, procurement, and business leaders all have a role to play. Infrastructure teams may own platforms and technical risk, but business teams still own the outcomes AI is meant to improve.
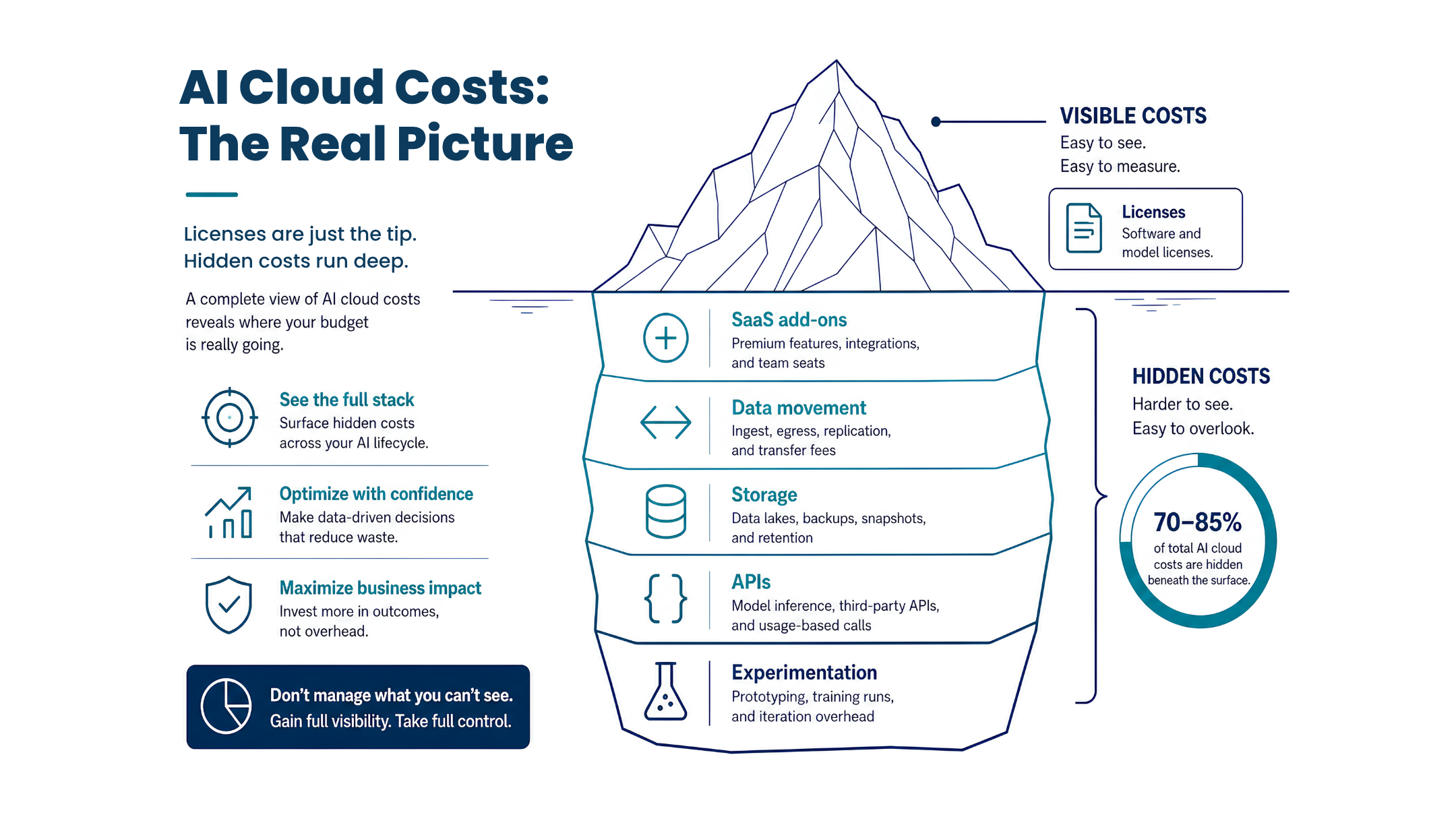
- Prioritize visibility early: You can’t govern what you can’t see. Good AI governance starts with visibility into which tools are in use, which models and features are being accessed, what data those tools touch, and how spending is changing over time.
- Use AI guardrails to enable progress: The point of AI guardrails is to give employees a safe, consistent path to follow. That includes approved tools, data boundaries, review triggers, and clear ways to request new use cases. Guardrails should make adoption safer and more intentional.
With these principles in place, you can structure the first 90 days into three focused phases.
Days 0–30: Define Scope, Policy, and Early AI Guardrails
Clarify What AI Includes in Your Environment
Start by defining scope. In many organizations, AI may already include:
- LLM chat tools, whether internal or external
- AI features embedded in SaaS platforms
- Internal copilots and agents built on enterprise data
- Third-party AI services used by business teams or vendors
Write down what is in scope for your initial AI governance effort. This keeps the first phase focused and prevents the program from trying to solve everything at once.
Stand Up a Lightweight AI Working Group
You don’t need a large committee, but you do need a place where decisions land. Many organizations start with a cross-functional group that includes IT, security, data, finance, or procurement, and one or two major business functions.
In the first 90 days, that group’s charter should be simple: create initial AI policies and guardrails, review or fast-track early AI use cases, and track where AI is spreading and where risk is emerging.
A monthly or biweekly cadence is usually enough to begin.
Draft a Simple Internal AI Use Policy
Your first policy doesn’t need to be complex. It does need to be clear enough for managers and employees to act on. Focus on three areas:
- Data rules, including what can be entered into external tools and what must remain internal
- Tool rules, including which AI tools are approved and how new tools are requested
- Behavior rules, including expectations for human review, accuracy checks, and disclosure in customer-facing work
A one-page policy is often enough to establish a baseline.
Create A Basic Inventory of AI Already in Use
In parallel, run a quick discovery effort across the business. Ask each business unit to list the tools, pilots, and features that already include AI, then work with major platform owners to identify which AI capabilities are enabled today. It is also a good idea to review contracts for references to AI, machine learning, or advanced analytics.
You will likely find more AI usage than expected. That is normal. The goal in the first 30 days is to create a map of what is happening today.
Days 31–60: Put AI Guardrails and Tollgates in Place and Add Ownership
With a foundation in place, the next 30 days are about shaping behavior.
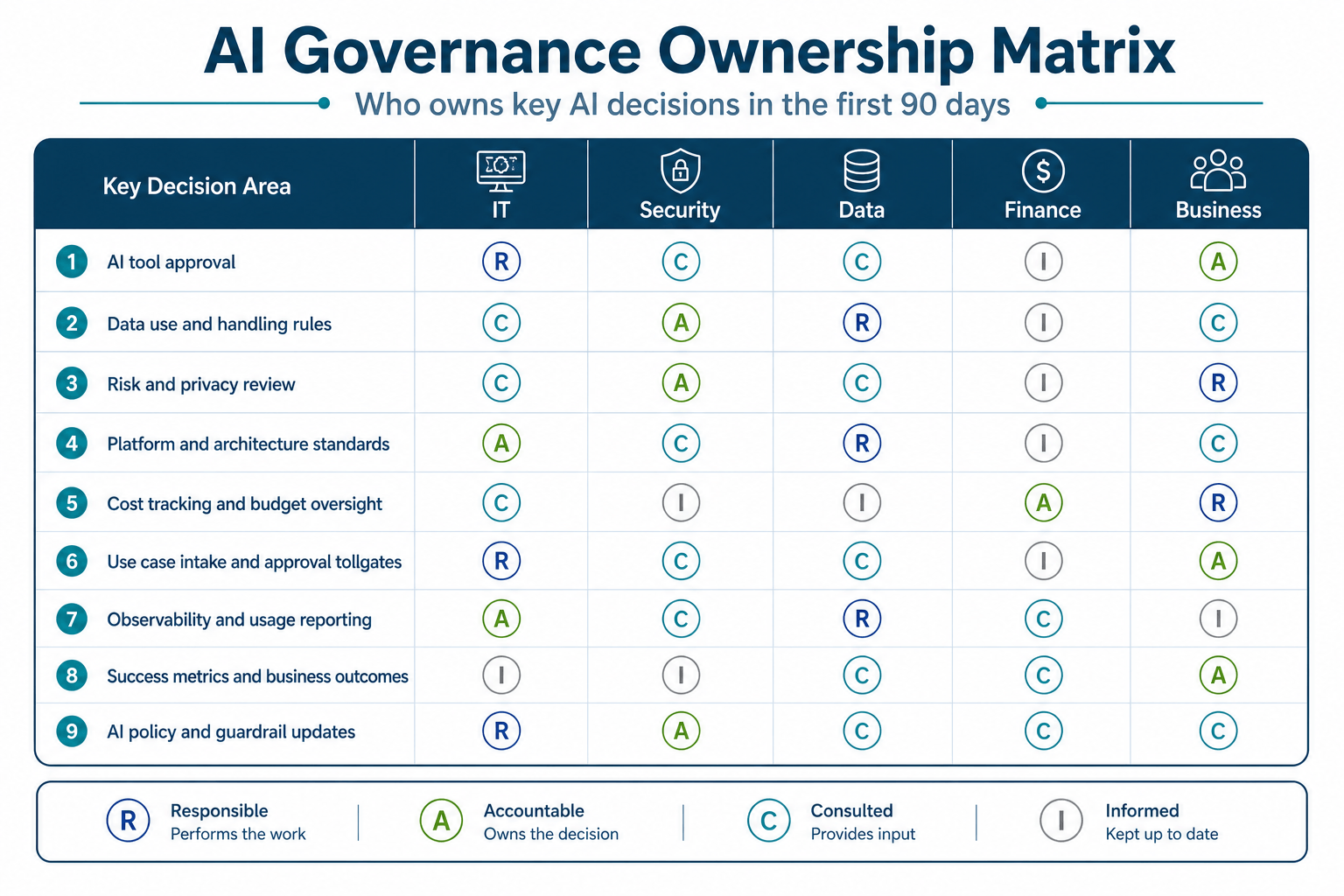
Define Ownership and Accountability
Clarify who owns what across a few core areas:
- Risk, usually led by security, privacy, and legal
- Platform and architecture, usually led by IT, data, and engineering
- Cost, usually shared by finance and business leadership
- Outcomes, owned by the business sponsor for each AI use case
A simple RACI goes a long way here. As AI adoption grows, some organizations also start considering more dedicated leadership roles, like a Chief AI Officer or Head of AI, to coordinate governance.
 Introduce a Simple Approval Tollgate
Introduce a Simple Approval Tollgate
Not every experiment should take months to review. At the same time, every new AI use case should clear a basic checkpoint and comply with basic diligence.
Create a simple, one-page intake form that captures:
- Business owner and sponsor
- What problem the AI is trying to solve
- Data sources involved
- Tools, vendors, or models involved
- Intended users
- Success metrics and review timeframe
From there, use a basic triage path. Low-risk internal experiments can move quickly. Higher-risk or external-facing use cases can trigger deeper review. These “approval tollgates” act as practical AI guardrails that catch obvious issues before they spread.
Build Observability into AI Usage
In the webinar discussion, we emphasized that ‘observability is a core part of governance, not an afterthought’.
In days 31–60, you just need to aim for basic visibility into:
- Which teams are using which AI tools and features
- How often those tools are being used
- Which models are involved in enterprise platforms
- What token or license consumption looks like over time
Depending on the environment, this may come from native admin dashboards, centralized logging, or partner platforms with stronger telemetry. Even a rough baseline is better than none.
Integrate AI into Existing Security Practices
No need to build a separate AI security program. Extending your existing review processes is a better approach that will save both time and effort.
This may include adding AI-specific questions to vendor and privacy reviews, updating the risk register to reflect concerns such as misuse and data leakage, and asking security testing partners to assess AI-powered interfaces and public chat experiences.
This keeps AI governance aligned with the broader security rhythm of the organization.
Days 61–90: Scale Literacy, Measurement, and Ongoing Governance
In the final 30 days of this first phase, shift from reactive governance to proactive enablement.
Launch an AI Literacy and Change-Management Push
Governance works best when employees understand the “why” behind it. It also depends on how comfortable people feel using AI at all. In the webinar, we noted that many employees, especially early-career talent, see AI as a threat or feel tools are being forced on them.
Practical steps you can take:
- Offer short trainings on safe, effective AI use in the tools you have approved
- Share examples of where AI is already helping teams remove tedious work
- Be explicit that AI is meant to augment people, not silently replace them
- Provide a clear path for employees to ask questions or raise concerns
This builds trust and reduces the temptation to bypass guardrails.
Define Early Success Metrics & Criteria
Measurement is where governance and value meet. In days 61–90, start tracking:
- Adoption: which teams and roles are using AI tools
- Operational impact: time saved, error reductions, or throughput increases
- Experience metrics: indicators like handle time, first-contact resolution, or deflection for CX use cases
- Cost signals: licenses, token consumption, and incremental infra spend
Each pilot should also have a defined decision point where you explore options to either scale it, extend it with changes, or sunset it and document what was learned.
Formalize A First-Pass AI Governance Playbook
By the end of the first 90 days, most organizations have enough experience to document how AI governance works today. That initial playbook should clearly capture roles and responsibilities, core policies and standards, approval and review paths, and the reporting leadership uses to stay informed.
This first version does not need to be perfect or permanent. It simply needs to reflect reality clearly enough for the organization to build from it. Think of it as “version 1” of a playbook you will refine every quarter.
Plan the Roadmap Beyond 90 Days
The first 90 days are only the beginning.
Once the basics are in place, the roadmap should expand to include other areas that need deeper work, such as model risk management for high-stakes decisions, closer alignment between AI, data architecture, and cloud strategy, stronger security testing, and governance for more advanced agentic systems.
It helps to summarize these into a roadmap that shows leaders that governance is an ongoing process.
Common Pitfalls in Early AI Governance (and How to Avoid Them)
Even with the best intentions, organizations can stumble in a few predictable ways.
Over-engineering the framework too early: Spending months designing a perfect framework before you have real use cases wastes time and creates rules that don’t match reality. Anchor your policies in what people are actually doing with AI today.
Focusing only on tools, not on data and processes: If your underlying data is dirty or your process is broken, AI will amplify the problem, not fix it. Make sure governance includes data quality and process ownership, not just tool approvals.
Ignoring employee sentiment: Forcing AI tools on reluctant teams or tying usage directly to performance can backfire and drive shadow AI instead of safe adoption. Treat literacy and change management as first-class parts of governance.
Treating governance as a “no” function: If every AI request turns into a lengthy blockade, people will route around the system. Use fast-track paths for low-risk experiments and focus on enabling safe patterns.
How Bluewave Helps Organizations Build AI Governance
You do not have to build this alone. Most IT and business leaders are already stretched thin managing cloud, security, and CX, even before AI enters the picture.
Bluewave’s role is to bring confidence and clarity to your technology decisions by:
- Helping you define the AI outcomes that matter, then working backward to policies and guardrails that support them
- Mapping your current state across cloud, SaaS, data, and contact center so you can see where AI is already in play and where the risks sit
- Connecting you with proven partners who can operationalize observability, automation, and security in your AI stack
From there, we help you turn AI governance into a repeatable practice that keeps AI safe, accountable, and aligned to real business value.
If you are ready to get ahead of AI risk and cost without slowing your teams down, we are here to help!
AI Governance FAQs
Q: What are AI guardrails?
A: AI guardrails are the policies, technical controls, review checkpoints, and usage rules that help employees use AI safely and consistently. They define approved tools, data boundaries, escalation paths, and expectations for oversight. In practical terms, AI guardrails give teams a safe path to follow as adoption expands.
Q: How are AI guardrails different from AI governance?
A: AI guardrails are one part of AI governance. Guardrails are the specific rules and controls that shape day-to-day use. AI governance is the broader operating model that defines ownership, accountability, policy, risk review, observability, measurement, and leadership oversight. In simple terms, guardrails are the controls, while governance is the full system around them.
Q: What should an AI governance framework include?
A: A practical AI governance framework should include ownership definitions, AI use policies, data handling rules, approval workflows, observability, risk review processes, and success metrics. It should also define how the organization updates these practices as AI use becomes more advanced.
Q: Who should own AI governance?
A: AI governance is usually shared. IT, security, data, finance, procurement, legal, and business leaders all play a role. A cross-functional working group often works well in the early stages, especially during the first 90 days.
Q: How quickly should organizations put AI guardrails in place?
A: As early as possible. AI guardrails are most effective when they are introduced alongside experimentation, not after widespread adoption is already underway. Lightweight guardrails can be established quickly and refined over time as the organization learns.