Hidden Sources of Cloud Spend Driving Up IT Costs
Cloud waste rarely shows up all at once. It builds up slowly, through forgotten resources, oversized workloads, unnecessary licensing, and weak governance, until one day, finance asks why cloud costs are 30% over budget.
While 30% may sound high at first glance, industry research suggests it is often closer to reality than many organizations expect. Reports from sources like Forbes show that many businesses underestimate just how much waste can accumulate in their environments without regular oversight and optimization.
The problem is not poor planning or because anyone missed something obvious. It is simply that cloud environments evolve faster than most teams can govern them. These environments get complex, teams stay busy, and small issues are easy to overlook until they start adding up.
Here are five of the most common sources of wasted cloud spend IT teams overlook until costs spiral.
Comparison of Waste Sources
| Waste Source | Prevalence | Monthly Cost Impact | Detection Difficulty | Mitigation Complexity |
| Idle Compute | Very High | $10K–$50K+ | Moderate | Moderate |
| Overprovisioning | High | $10K–$40K+ | Moderate | Moderate |
| Unused Storage | High | $1K–$10K | Easy | Easy |
| Networking/ Egress | Medium | $5K–$20K | Medium | Medium |
| Unused Commitments | Medium | $10K–$40K | High | Medium |
Why This Matters: Every dollar wasted in Azure, AWS, or Microsoft 365 is budget that could be reinvested into security, modernization, AI initiatives, or infrastructure improvements.
Zombie VMs: Paying for Machines No One Is Using
Powered-off virtual machines are one of the most common and costly sources of cloud waste, and one of the easiest to overlook. When a VM is deallocated, it stops running, but its managed disks continue to incur charges. At roughly $70–$140 per mid-range VM per month in managed disk charges alone, the cost adds up quickly across a large environment.
In a recent assessment, Bluewave identified more than 100 Azure VMs in a deallocated state. None of them were in active load balancers or scale sets, which suggested they had been abandoned rather than intentionally retained. Retiring those VMs and their associated disks represented projected savings of $10,007 per month.
The pattern is familiar. Resources get created for a project, test, or migration and are never formally decommissioned. Without automated tagging and idle-resource policies, they stay in the environment and continue billing indefinitely.
Why IT teams miss it: There is no alert that says a VM has been off for 90 days. Unless someone is proactively looking for it, it often goes unnoticed.
How to spot it: IT Teams can implement reviews that cover VMs that have remained deallocated or powered off for 30+ days, audit managed disks that are no longer attached to an active workload, or simply look for resources without an owner or expiration tags.
Underutilized Compute: Paying for Capacity You Don’t Need
Most IT teams understand the value of rightsizing. The challenge is that it usually is not revisited often enough. As a result, a meaningful share of running VMs continues operating at a fraction of the capacity being paid for.
In assessments, Bluewave often finds that 20 to 30% of Azure VMs show sustained low CPU and memory utilization, consistently below the thresholds that justify their current SKU size. Downsizing those VMs by one or two tiers, based on actual usage data, can yield $3,000 to $7,000 per month in savings, with relatively low operational risk when done in a controlled sequence.
Non-production environments make the problem worse. Dev and test VMs often run 24/7 on the same schedule as production, even when developers are not working. Applying off-hours schedules to non-production workloads can recover another 2 to 4% of compute spend.
Why IT teams miss it: Rightsizing depends on current utilization data and someone with the time and authority to act on it. Many teams do it once during migration and then move on.
How to spot it: Review CPU and memory utilization over the last 30–90 days to identify VMs consistently running below 40% capacity. Compare workload demand to current VM sizing and audit dev/test environments operating outside business hours.
Microsoft 365 License Waste: Spend That Slips Through the Cracks
SaaS licensing is often managed separately from infrastructure spend, which means it may not get the same level of scrutiny as compute and storage. Over time, that creates a steady build-up of waste that is easy to identify once someone takes a closer look.
Two issues account for much of the M365 waste Bluewave finds:
- Disabled accounts still holding licenses. When employees leave or are deactivated, their licenses often are not removed. In one client assessment, Bluewave identified $7,620.30 per month in M365 licenses assigned to disabled accounts that were no longer active but had never been cleaned up.
- Overlapping license assignments. When users hold multiple license tiers, such as both an E3 and an E5, or a suite license plus redundant add-ons, the organization pays for coverage it already has. In the same assessment, overlapping assignments accounted for $22,080.96 per month in avoidable spend.
Combined, those licensing issues represented nearly $30,000 per month in avoidable spend, with low remediation risk and no operational disruption required to fix them.
Why IT teams miss it: License management often sits between IT and HR, with no single owner. Offboarding workflows also rarely include an automated license reclamation step. In many cases, licenses are left active because teams worry about losing files or data tied to individual user accounts and lack a clear process for transferring or preserving that information before deprovisioning.
How to spot it: Audit disabled or inactive user accounts that still have licenses assigned and review overlapping license tiers or add-ons. Compare assigned licenses against actual usage to identify users paying for more functionality than they need.
Unmanaged Observability and Storage Costs: Infrastructure That Rarely Gets Reviewed
Log analytics workspaces and blob storage are foundational to cloud operations, but they are also commonly over-provisioned. Retention periods are set during deployment and never revisited. Cold data stays in hot-tier storage. Noisy log categories continue to ingest data even when no one is using it.
In assessments, Bluewave finds that Log Analytics retention and ingestion adjustments alone can yield $1,200 to $2,700 per month in savings, often through configuration-only changes that carry low operational risk.
Storage is another frequent source of waste. Applying lifecycle management policies to move infrequently accessed blob data to Cool or Archive tiers can deliver 20 to 60 % savings on cold storage, estimated at $1,000 to $2,500 per month, depending on data volume.
Why IT teams miss it: These services tend to be treated like background infrastructure. Because they do not feel like core compute, they are often left out of cost optimization reviews.
How to spot it: Review log retention settings and ingestion rates to identify noisy or unnecessary data collection. Audit storage for cold data still sitting in hot-tier environments or files that have not been accessed in 90+ days.
Weak Governance and Visibility: Why Cloud Waste Keeps Coming Back
Most of the issues on this list trace back to the same underlying problem: cloud environments that have grown without the governance controls needed to manage them well.
Without a tagging strategy, there is no clear ownership. Without budget alerts, overruns can go undetected. Without automated policies, waste returns as quickly as it is cleaned up.
In one assessment, Bluewave found:
- An Azure environment forecasted to run at $75,227 for the month against an $18,204 monthly budget.
- A 313% overrun, with no automated mechanism in place to detect or correct the drift.
The cost explorer was accessible, but it was not being reviewed. A budget had been set, but no one was acting on it.
Governance is what makes cost optimization sustainable. Without enforced tagging, ownership policies, anomaly alerts, and regular license sweeps, cleanup becomes temporary and the waste returns.
Why IT teams miss it: Governance work competes with active priorities. It does not resolve a ticket or launch a feature, so it often gets pushed aside until a larger problem forces attention.
How to spot it: Identify resources missing ownership tags and review whether budgets, alerts, and governance policies are actively configured. Assess how often cloud spend reports are reviewed and whether stakeholders are acting on the data.

Cloud Spend Closing Thoughts
Organizations that control cloud spend effectively are not the ones that optimize once and consider the job done. They are the ones who operationalize optimization through continuous review and routine performance assessments that adapt alongside the environment.
As cloud infrastructure grows and changes, long-term cost efficiency depends on building optimization into everyday operations.
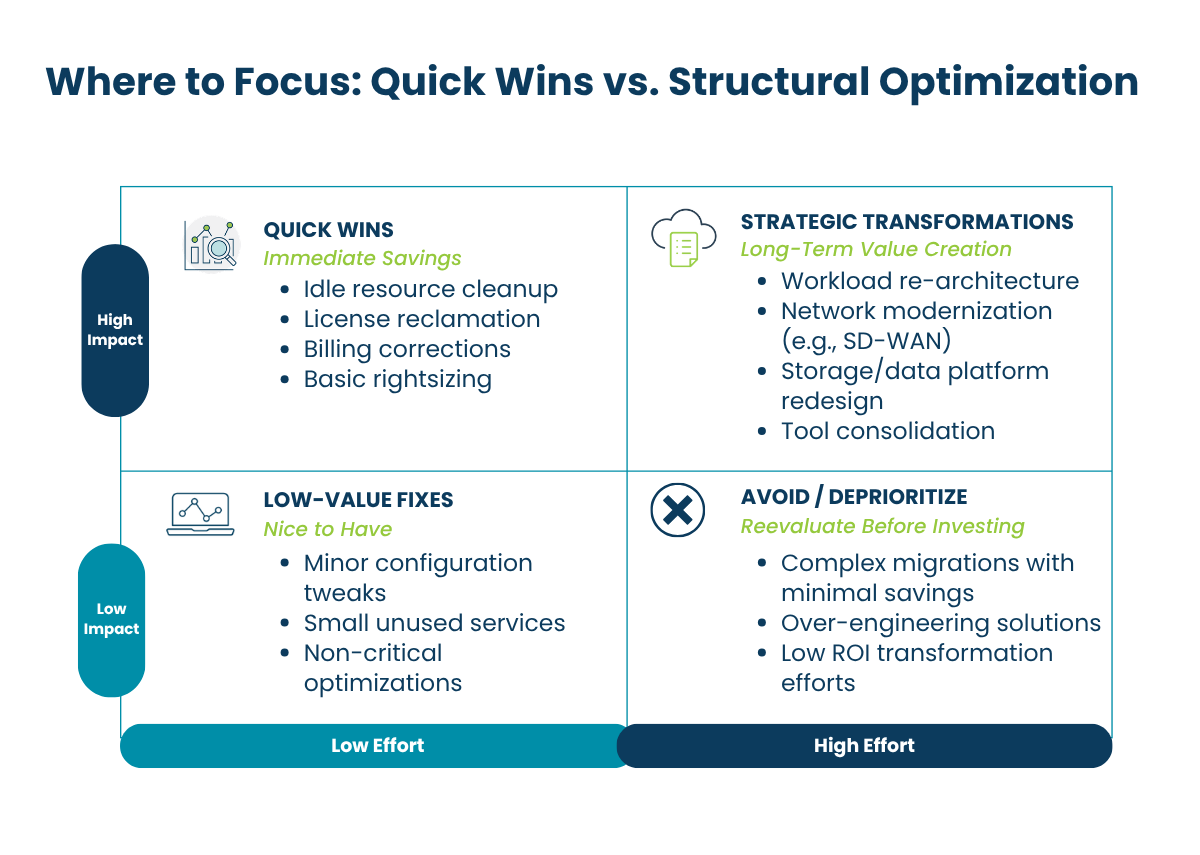
Identifying the most common sources of cloud waste is an important first step, but the bigger question is what to do next. Once you know where the waste is hiding, you need a practical way to prioritize fixes, reduce risk, and turn findings into measurable savings.
In the next article, we walk through a cloud optimization roadmap for what comes after the waste is identified.
What We Can Do About It
The fastest way to reduce wasted cloud spend is to start with visibility. The upside is that most of these issues can be found and fixed through a structured assessment.
Bluewave’s Cloud Assessment Framework helps organizations uncover hidden waste across infrastructure, licensing, storage, governance, and workload efficiency. Then delivers a prioritized roadmap to reduce spend without disrupting operations.
Schedule a Cloud Assessment to identify where your environment may be overspending.
Cloud Spend FAQ
How much cloud spend is typically wasted?
Most organizations waste 20–30% of cloud spend due to inefficiencies.
What is the biggest cause of cloud overspending?
Underutilized compute and poor governance are the most common contributors.
How often should cloud costs be reviewed?
Monthly reviews are recommended, with quarterly optimization audits.